Machine learning is already embedded across US businesses, shaping forecasting, recommendations, fraud detection, search ranking, and AI-generated answers. This guide highlights the key US-focused statistics, adoption trends, cost realities, and performance risks that define how machine learning is actually used across industries today.
Psyke helps teams turn these machine learning-driven shifts in search and discovery into structured content strategies built for visibility across search engines and AI systems.
Machine learning, artificial intelligence, and deep learning get used interchangeably but they mean different things. Understanding these distinctions matters when evaluating vendors, interpreting performance claims, and setting realistic expectations.
Machine Learning vs AI vs Deep Learning
Artificial Intelligence
Artificial Intelligence is the broadest category, any computer system mimicking human intelligence. The global AI market reached $244 billion in 2025 and is expected to exceed $800 billion by 2030, according to Statista.
Deep Learning
Deep Learning is a specialized ML subset using multi-layered neural networks for complex data like images and speech. Traditional ML runs on modest infrastructure with smaller datasets; deep learning demands large-scale data and computation.
Machine Learning
Machine Learning is a subset of AI. Rather than following programmed rules, ML models identify patterns in data and apply them to make predictions. In the AI software development market, machine learning accounted for 36.7% of technology adoption in 2024, making it the largest single category, according to Grand View Research.
The Three Types of Machine Learning
Supervised learning uses labeled data where inputs have known outcomes, ideal for fraud detection, churn prediction, and medical diagnosis.
Unsupervised learning discovers patterns in unlabeled data, used for customer segmentation, recommendation engines, and anomaly detection.
Reinforcement learning trains through trial and feedback, applied in autonomous systems, dynamic pricing, and game AI. It requires significantly more computational resources.
Why Data Quality Determines Success
Data preparation consumes up to 80% of machine learning project time, according to AWS. Pragmatic Institute confirms data scientists spend 60-80% of time on data collection and cleaning.
For a 100,000-sample dataset, organizations typically invest 80-160 hours addressing quality issues, 300-850 hours for annotation, and $25,000-$65,000 total preparation costs, according to Debut Infotech.
This explains why 73% cite data quality as their biggest AI challenge and why 85% of ML projects fail. Real-world data changes over time, causing data drift where incoming data no longer reflects training conditions.
Machine Learning Adoption in the United States
Machine learning adoption in US companies accelerated sharply during 2023–2025, driven by accessible cloud infrastructure, pre-built models, and growing enterprise interest in generative capabilities. The United States represents the world’s largest machine learning market, yet significant gaps remain between pilot programs and production deployment.
Market Size and Growth Trajectory
The US leads globally in machine learning investment:
Machine Learning Deployment Patterns by Industry and Function
Machine learning adoption is most prevalent in technology, media and telecommunications, and healthcare. Within these industries, deployments tend to concentrate in functions tied directly to competitive advantage.
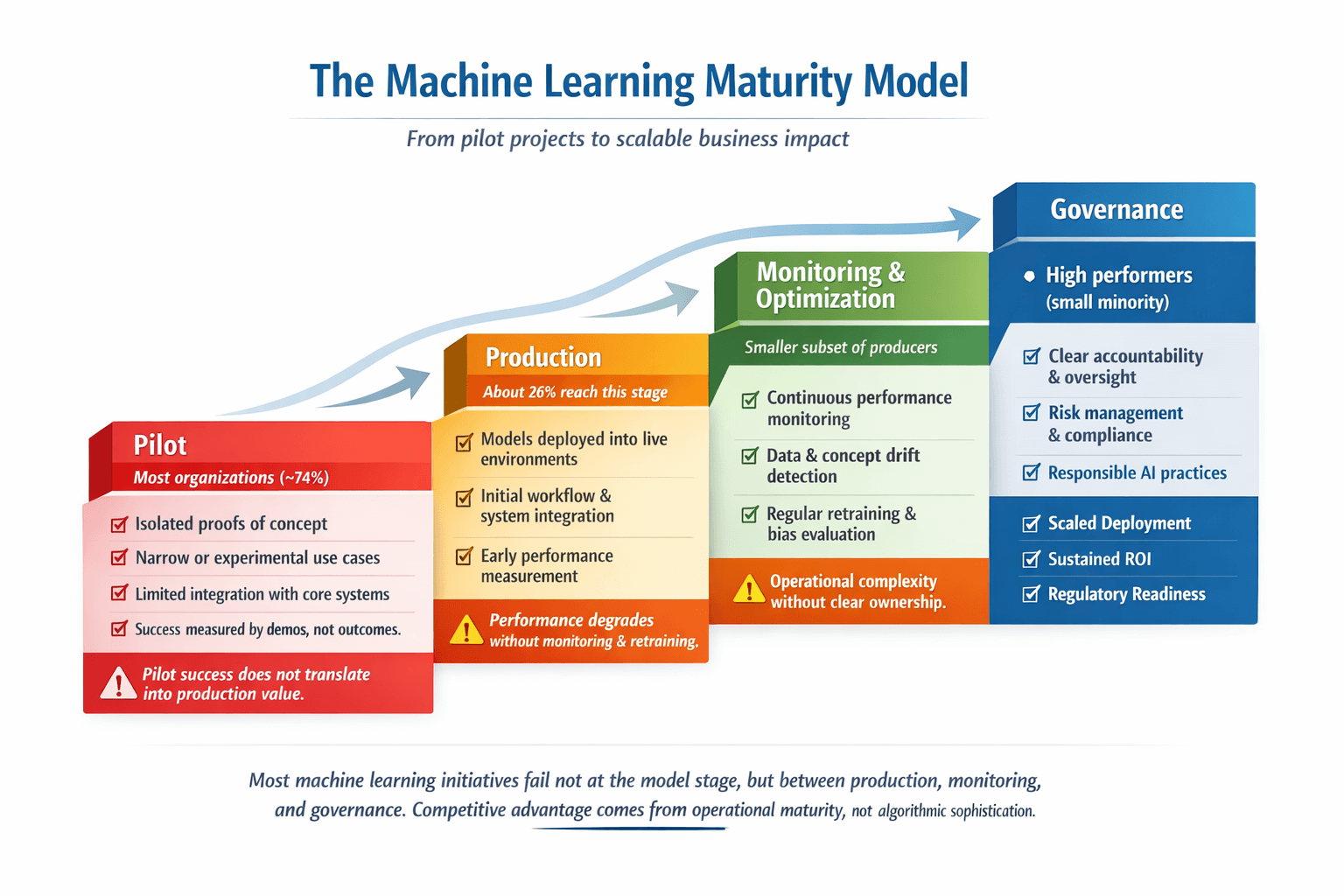
Only 26% have moved beyond pilots to generate tangible business value
74% of companies struggle to achieve and scale value from AI
Just 4% have cutting-edge AI capabilities enterprise-wide
This gap explains why headline adoption statistics often overstate real operational impact.
Enterprise Adoption Rates
According to McKinsey, 78% of organizations now use AI in at least one business function, up from 72% in early 2024 and 55% in 2023.
However, adoption depth varies widely depending on how it is measured. Data from the US Census Bureau, which tracks firms using AI to produce goods or services, shows adoption rising from 3.7% in September 2023 to 5.4% by February 2024. This gap highlights the difference between experimentation and production-level use.
Company size plays a significant role in adoption depth. Large enterprises are far more likely to deploy machine learning in production environments, while small and mid-sized firms remain concentrated in pilots and limited-function implementations.
Scaling Challenges:
Machine learning adoption is widespread, but scaling it successfully is not. Most organizations run multiple initiatives at once, yet only a fraction ever make it into production.
The difference isn’t experimentation. It’s operational maturity, the ability to deploy, monitor, and scale machine learning systems reliably.
This is where Psyke comes in. We help teams adapt how they communicate and structure information so it aligns with how AI systems evaluate and surface content.
Machine learning adoption has reached 78% of organizations, yet meaningful financial impact remains concentrated among a small group of high performers who approach ML as strategic transformation rather than tactical automation.
56% with positive ROI see measurable financial performance improvement
Only 39% report EBIT impact at the enterprise level
Just 5% achieve "high performer" status with 5%+ EBIT contribution
High performers redesign workflows rather than automate existing processes.
Industry-Specific Returns
Banking shows the clearest quantified opportunity, with generative AI positioned to add $200-340 billion annually (2.8-4.7% of total industry revenues), according to McKinsey Global Institute.
Timeline and Investment Reality
Most organizations require 2-4 years to achieve satisfactory ROI—significantly longer than the typical 7-12 month technology payback period, according to Wharton research. Productivity gains don't automatically convert to bottom-line results without workflow redesign.
Workers save 5.4% of work hours (2.2 hours per 40-hour week)
Frequent users save over 9 hours weekly
Daily users: 1 in 3 save at least 4 hours per week
Organizations achieving substantial gains embed AI in daily workflows rather than occasional experimentation.
The Machine Learning Failure Rate Nobody Discusses
Machine learning adoption has accelerated rapidly across US organizations, yet most initiatives still fail to deliver sustained business value. While pilots and proofs of concept are widespread, only a minority of organizations successfully operationalize machine learning at scale. This gap between experimentation and impact defines the current ML landscape.
Most machine learning failures are operational, not technical.
The Production Gap
Multiple enterprise studies show that moving from pilot to production is the hardest stage of machine learning adoption. Research from Boston Consulting Group, McKinsey & Company, and MIT consistently finds that while experimentation with AI and machine learning is common, only a small percentage of initiatives translate into measurable financial impact.
BCG’s research shows that only about 26% of organizations move beyond pilots to generate tangible business value, while the remaining majority struggle to scale successful use cases across the enterprise. McKinsey reports similar findings, noting that widespread AI adoption has not resulted in proportional gains in enterprise-level EBIT for most organizations.
Research from MIT’s Sloan and NANDA initiatives further highlights that the vast majority of generative AI pilots fail to deliver measurable profit-and-loss impact, reinforcing that early technical success does not guarantee commercial outcomes.
The Core Insight
The defining factor behind machine learning success is operational maturity, not algorithmic sophistication.
Organizations that succeed invest early in data infrastructure, deployment pipelines, monitoring processes, and governance frameworks. Those that do not often accumulate disconnected pilots that never scale, regardless of how advanced the underlying models may be.
Machine learning does not fail because it is inaccurate.
It fails because most organizations are not structured to operate it continuously.
This reality explains why adoption alone is no longer a competitive advantage and sets the foundation for understanding what production-ready machine learning actually requires—continuous monitoring, retraining, and governance—which the next section explores in detail.
Why Most ML Initiatives Fail
Contrary to common assumptions, machine learning projects rarely fail because of model accuracy alone. Enterprise research points instead to operational and organizational barriers as the primary causes.
Studies and surveys from Pragmatic Institute show that data scientists spend 60–80% of their time on data collection, cleaning, and preparation, leaving limited capacity for modeling, optimization, and evaluation. Complementary research from Second Talent finds that data quality is the most frequently cited barrier to successful AI and machine learning implementation.
Deployment and integration challenges compound these issues. Enterprise adoption studies from Information Services Group (ISG) indicate that while some AI use cases reach production, many stall due to integration complexity, unclear ownership, or lack of ongoing performance measurement once models are live.
Machine Learning Performance in Production
Moving machine learning models from development to production introduces challenges that extend beyond initial accuracy metrics. Production environments demand continuous monitoring, bias mitigation, and governance frameworks to maintain performance and trust at scale.
Model Drift and Continuous Monitoring
Machine learning models do not maintain static performance. Changes in input data distributions and shifts in underlying relationships between inputs and outputs cause model performance to degrade over time if left unmanaged.
Production ML requires monitoring infrastructure to be in place before deployment, not after issues appear. Organisations that succeed at scale implement observability platforms that track performance metrics, data quality, system health, business KPIs, fairness metrics, and data lineage on an ongoing basis.
Industry guidance from AWS MLOps guidance and Google Cloud MLOps best practices, highlights the need to establish baseline performance metrics, automate drift detection, document retraining processes, and continuously monitor both statistical drift and concept drift.
Retraining frequency varies by use case volatility:
The true cost of machine learning emerges after deployment, not during experimentation. While pilots and proofs of concept often appear inexpensive, production systems introduce ongoing operational expenses that scale with usage, data volume, and organizational complexity.
In production environments, machine learning costs are driven by:
Data preparation and refresh cycles, including continuous ingestion, cleaning, labeling, and validation of new data
Inference and serving costs, particularly for high-volume, real-time, or low-latency use cases
Compute costs for model training, fine-tuning, and retraining as data and conditions change
Monitoring and observability infrastructure to track model performance, drift, reliability, and business impact
Governance and documentation overhead, including risk management, auditability, and compliance requirements
Security, privacy, and access controls, especially in regulated industries
These cost drivers compound over time. As usage increases, organizations incur recurring expenses across infrastructure, tooling, and human oversight. This is why machine learning economics depend less on model choice and more on operational discipline. Many initiatives appear cost-effective in pilot stages, only to exceed initial budget expectations once models are deployed, monitored, retrained, and governed in real-world conditions.
Models trained on historical data can encode historical biases, perpetuating discrimination across hiring, credit scoring, healthcare diagnosis, and other high-stakes applications. Production accuracy concerns go beyond aggregate metrics—models may perform well overall while systematically failing for specific demographic groups.
77% of businesses worry about AI hallucinations and accuracy issues, according to AIMultiple research. These concerns intensify in production environments where incorrect outputs directly impact users and business outcomes.
Bias mitigation requires systematic approaches including diverse training data, regular fairness testing across demographic groups, human oversight for high-stakes decisions, and comprehensive documentation of model limitations and known failure modes.
Governance Frameworks for Production ML
As machine learning systems scale, governance becomes a functional requirement rather than a compliance formality.
The NIST AI Risk Management Framework, released January 2023 and updated March 2025, provides structured governance through four core functions:
The March 2025 updates emphasize model provenance, data integrity verification, third-party assessment requirements, and GenAI-specific risks including prompt injection and adversarial manipulation. Sources: IS Partners, Diligent
Governance trends from recent industry research indicate increasing adoption of Chief AI Officer roles to coordinate technical, operational, and ethical requirements across organizations. Wharton research documents this executive-level recognition that ML success requires centralized governance. Organizations report that Responsible AI practices boost ROI when implemented systematically, though many struggle with operationalizing frameworks, according to PwC.
Production machine learning success depends less on initial model sophistication than on an organization’s ability to monitor, govern, and adapt systems continuously as real-world conditions change.
GOVERN
Define organizational structures, processes, roles, and accountability for AI systems
Implement testing protocols, track performance metrics, conduct bias testing, and validate model behavior
MAP
Identify context, stakeholders, potential impacts, and risk boundaries before deployment
How Machine Learning Is Changing Search and Discovery
From Keywords to Semantic Understanding
Google's ML-powered ranking systems, including RankBrain, BERT, MUM, and neural matching, prioritize semantic understanding over keyword matching, according to Google's ranking systems guide.
RankBrain, deployed in 2015, understands how words relate to concepts rather than simply matching keywords.
BERT comprehends how word combinations express complex ideas and ensures important words aren't dropped from queries.
MUM, 1,000 times more powerful than BERT, can understand information across text and images and is used for specific applications like COVID-19 vaccine information.
These systems analyze content comprehensiveness, user engagement, technical performance, and authority signals, moving beyond keyword density.
The Zero-Click AI Answer Trend
Google AI Overviews (powered by Gemini) represent one of Search's most successful launches but reduce website clicks by 30-47%, according to Pew Research Center analysis. AI Overviews now reach 2 billion monthly users worldwide, fundamentally changing traffic patterns.
Discovery has fragmented across multiple platforms:
ChatGPT serves 800 million weekly users as a primary research and discovery tool
AI platforms like ChatGPT and Perplexity drove 1.13 billion referral visits in June 2025 alone
Google maintains dominant search market share with billions of daily searches
Despite zero-click trends, the SEO services market reached $74.9 billion in 2025 and projects to $127.3 billion by 2030, according to Mordor Intelligence, indicating businesses continue investing heavily in organic visibility even as discovery mechanisms evolve.
Visibility in search is now shaped by machine learning, not keywords alone.
As search systems shift from keyword matching to machine learning interpretation, content strategy must evolve from optimization for rankings to optimization for understanding.
ML-driven visibility requires fundamental shifts:
Entity-Based Optimization
Content connected to recognized entities with structured data markup
Structured Data
Schema markup helps ML systems parse content
Technical Performance
Core Web Vitals compliance, fast page loads, mobile-first design
Question-formatted headings with concise answers followed by comprehensive depth
Measuring Performance in ML-Driven Search
Traditional analytics cannot measure machine learning's impact on discovery. When AI delivers answers without clicks and platforms don't attribute sources, organizations need new measurement approaches.
Why Attribution Is Difficult
Google Search Console doesn't label ML-influenced queries. AI platforms don't provide source attribution. Zero-click answers don't generate measurable traffic. Multi-platform discovery fragments traditional tracking.
As a result, organizations must rely on indirect signals that indicate whether machine learning systems understand, surface, and prioritize their content—even when clicks never occur.
Entity Recognition (branded search volume, "People Also Ask")
AI Platform Citations (manual testing: ChatGPT, Perplexity, AI Overviews)
Multi-Platform Referral Traffic from AI sources
How Psyke Helps Brands Adapt to ML-Shaped Discovery
Machine learning driven discovery requires content that is structured for algorithmic interpretation, not just human reading. Visibility now depends on how clearly systems can understand, contextualise, and trust information.
It rewards clarity, structure, and authority. Psyke builds all three by designing content systems that are easy for AI models to parse, cite, and surface across search and generative platforms.
We help brands move from keyword focused optimisation to machine readable, semantically structured content that supports discovery at scale.
Entity-Based Content Architecture
Structure content around recognized entities. Create topic clusters demonstrating expertise. Establish entity relationships through internal linking.
Continuous Optimization
Regular content audits, performance monitoring, algorithm updates, and iterative improvement.
Technical Performance
Ensure Core Web Vitals compliance, fast loads, mobile-first design, and structured URL architecture.
Multi-Platform Visibility
Optimize across Google Search, AI Chatbots, Voice Assistants, and Recommendation Systems.
Answer-First Content Frameworks
Create question-formatted headings with concise answers, comprehensive elaboration, and natural language—meeting requirements of extractable answers within authoritative content.
Structured Data Implementation
Deploy comprehensive Schema markup helping ML systems accurately categorize and surface content.
Winning ML-driven discovery requires systems, structure, and sustained execution, not tactics. Start optimizing for ML-powered discovery.
Machine learning is a subset of artificial intelligence that allows systems to learn patterns from data and make predictions or decisions without being explicitly programmed. Businesses use machine learning to make predictions, automate decisions, and power systems like recommendations, fraud detection, and search ranking.
How is machine learning different from AI?
Artificial intelligence (AI) is the broader field of creating systems that mimic human intelligence. Machine learning is a specific approach within AI that focuses on learning from data. All machine learning is AI, but not all AI systems rely on machine learning.
Why do most machine learning projects fail?
What does it take to run machine learning successfully in production?
How does machine learning affect search and content discovery?
Most machine learning projects fail due to operational challenges rather than technical limitations. Common problems include poor data quality, difficulty moving from pilots to production, lack of monitoring and retraining, and unclear ownership of governance and ROI.
Running machine learning in production requires continuous work. Organizations must monitor model performance, detect data changes, retrain models as conditions evolve, manage bias and risk, and apply governance frameworks that define accountability and oversight.
Machine learning has changed how search engines and AI systems surface information. Instead of matching keywords, they focus on understanding meaning, entities, and intent, and often provide direct answers through AI interfaces without sending users to websites.
The Outlook: Machine Learning and the Next Era of Discovery
Machine learning has moved from experimentation to infrastructure. It now plays a central role in how people discover information and how platforms decide what gets surfaced.
For brands, visibility is no longer about ranking broadly. It depends on being structured, authoritative, and clear enough to be selected as the answer by machine learning systems that increasingly choose one source rather than many.
The shift is fundamental. Brands now compete for understanding, not just rankings.
Key trends shaping 2026:
AI Overview expansion across search and discovery platforms
Increasing fragmentation across search, AI assistants, and referral channels
Entity based optimisation becoming essential for visibility
Governance maturity separating leaders from laggards
Model drift management becoming a core operational requirement
Organizations that succeed will treat machine learning as operational infrastructure. This means structuring content for algorithmic interpretation, investing in monitoring and governance, and maintaining systems continuously rather than reactively.
This is where Psyke comes in. Psyke helps brands adapt to machine learning driven discovery by designing content systems built for scale, clarity, and long term visibility.
Machine learning is no longer optional infrastructure. It is the gatekeeper of visibility.